imkeo.app,tp117.app,btp3.app,tp114.app,bit114.app,tp115.app,bit115.app,imkei.app,tp116.app,btp1.app,btp1.app,im777.app,im555.app,im222.app,im666.app,im444.app,tcoken.im,im333.app,im83.app,tp666.app,tp77.app,tp11.app,tp666.app,tp99.app
如今,数据隐私问题备受重视。联邦学习这种技术,它不需要共享原始数据,却能实现多方共同训练模型,显得尤为珍贵。它既保证了隐私安全,又促进了合作训练,这也是它备受瞩目的一大优势。
联邦学习的基础架构
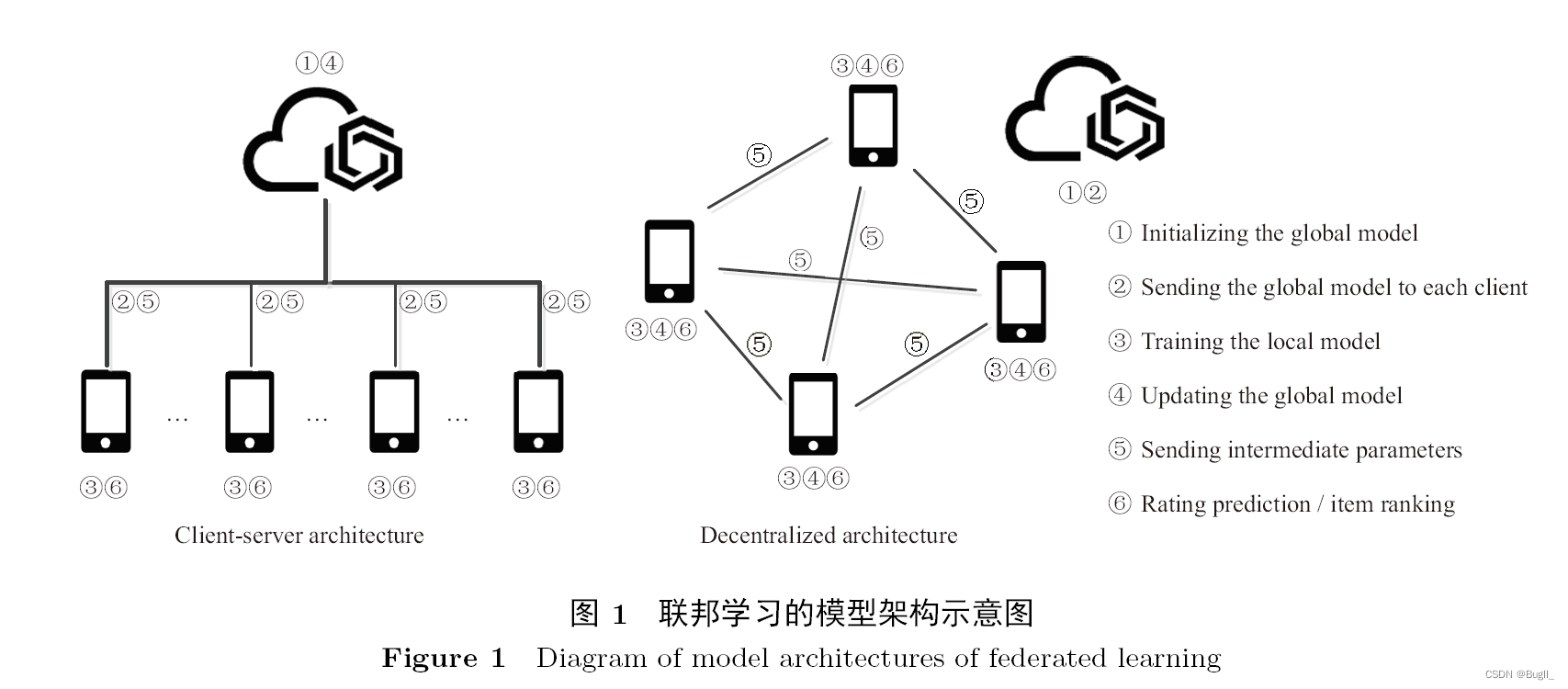
联邦学习模式中,众多参与者可以共同训练模型而不必泄露各自的数据隐私。比如,在医疗数据的研究合作中,不同地区的医院作为参与者,各自掌握着大量的病人信息,这些信息涉及个人隐私,极其宝贵。然而,在联邦学习体系中,各方可不交换原始数据,仅通过数据特征联合训练模型。这种做法与传统分布式学习框架形成鲜明对比,后者中各方的数据控制能力相对较弱。
去中心化架构在联邦学习中扮演关键角色。许多初创企业的合作项目,由于缺乏大型服务端资源,便选择了这种架构。在这种架构中,服务端只负责提供初始模型参数或帮助通信,并不负责更新模型。虽然这种架构与客户端-服务端架构存在差异,但它们在确保客户端原始数据不外泄至外部这一点上是一致的。
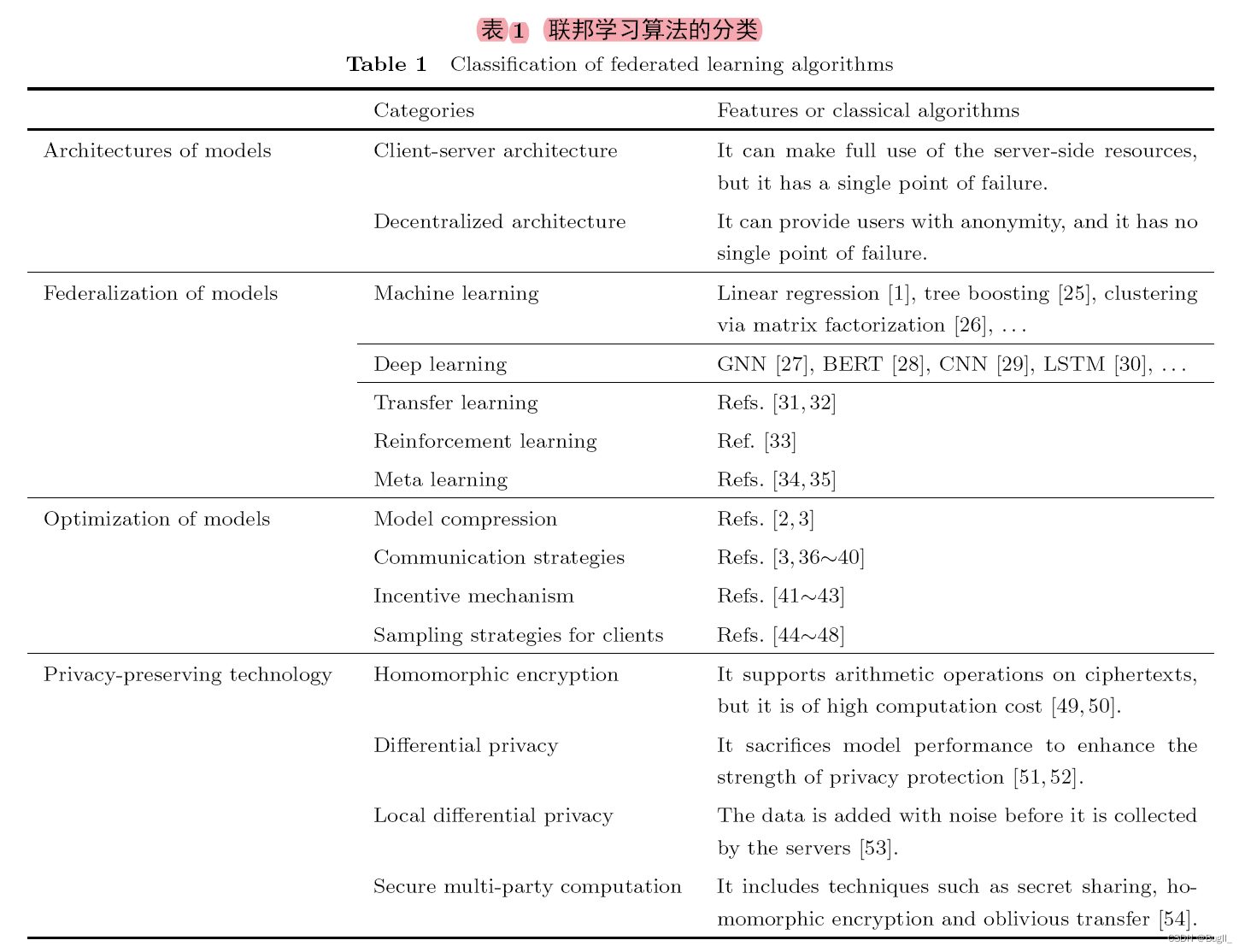
推荐算法的基本分类
推荐算法依据用户过往互动的物品相似度来给出建议。比如,音乐软件会根据用户过往喜欢的歌曲类型来推荐相似曲目。其关键在于寻找相似物品。这种算法在处理新物品推荐方面表现突出。协同过滤算法则更关注用户喜好的相似性。例如,电商网站会根据拥有相似喜好的用户群体购买过的商品来推荐给用户。它包括基于邻近用户和基于模型的方法,尽管考虑了用户间的偏好关系,但同样面临用户和物品的冷启动挑战。
推荐算法的架构特点
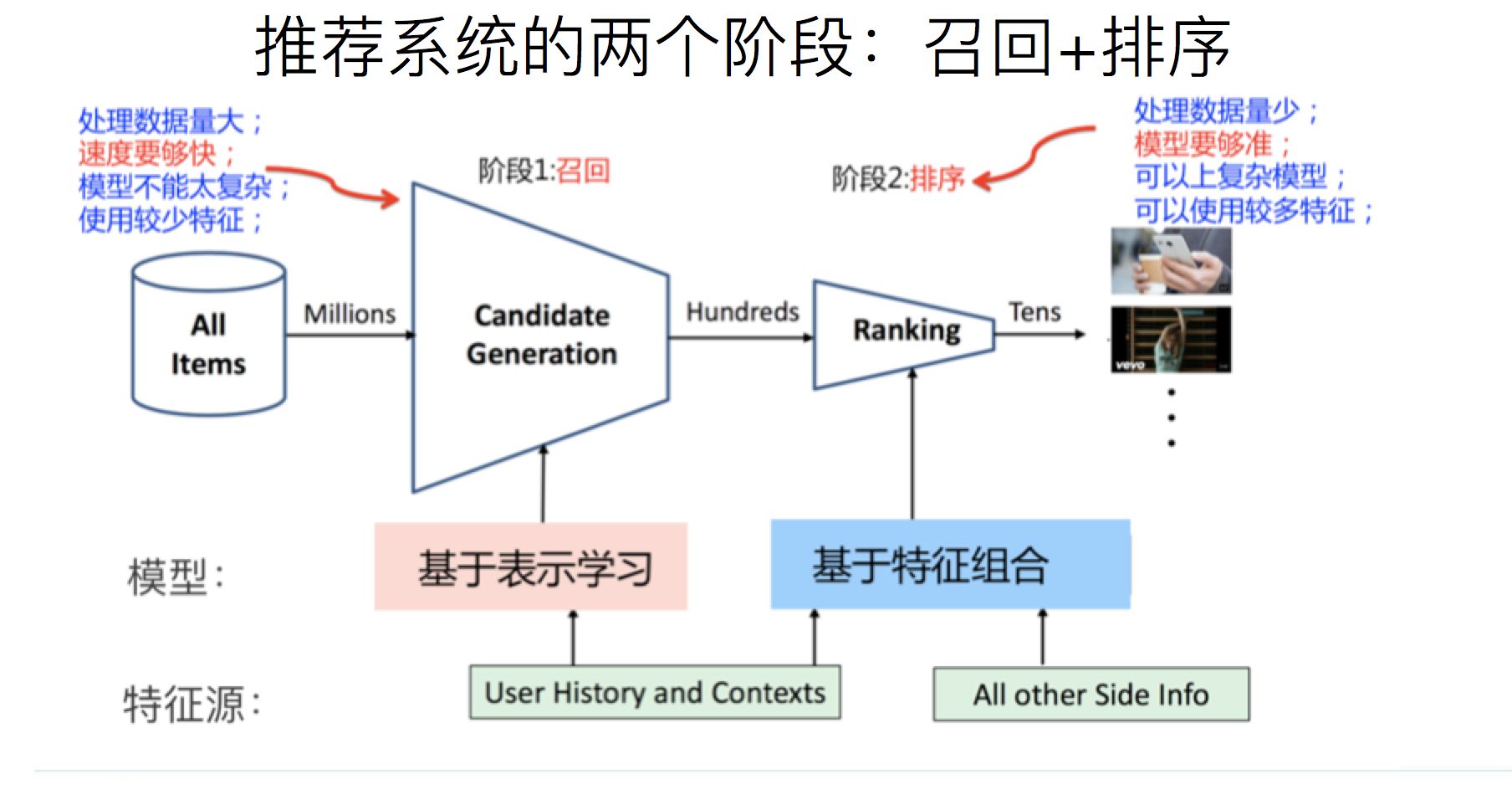
推荐算法普遍采用集中式设计。在流媒体平台上,用户仅作为客户端,负责生成和传输数据,比如播放记录等。而服务端则承担数据处理和模型构建的任务。在此过程中,服务端在收集节点原始数据和模型参数时,隐私保护并非首要考虑的问题。
联邦推荐的现状
当前联邦推荐研究还处于初级阶段。多数联邦推荐算法源自对传统推荐模型的改造。类似地,众多科研团队也在对传统评分模型进行改良。这样做的主要目的是为了保护用户的隐私。然而,在联邦学习领域,关于通信成本、计算效率和激励机制等问题,在联邦推荐算法的设计中关注不足。但在模型实际训练和部署过程中,这些问题却产生了重大影响。
联邦推荐系统的多种情况
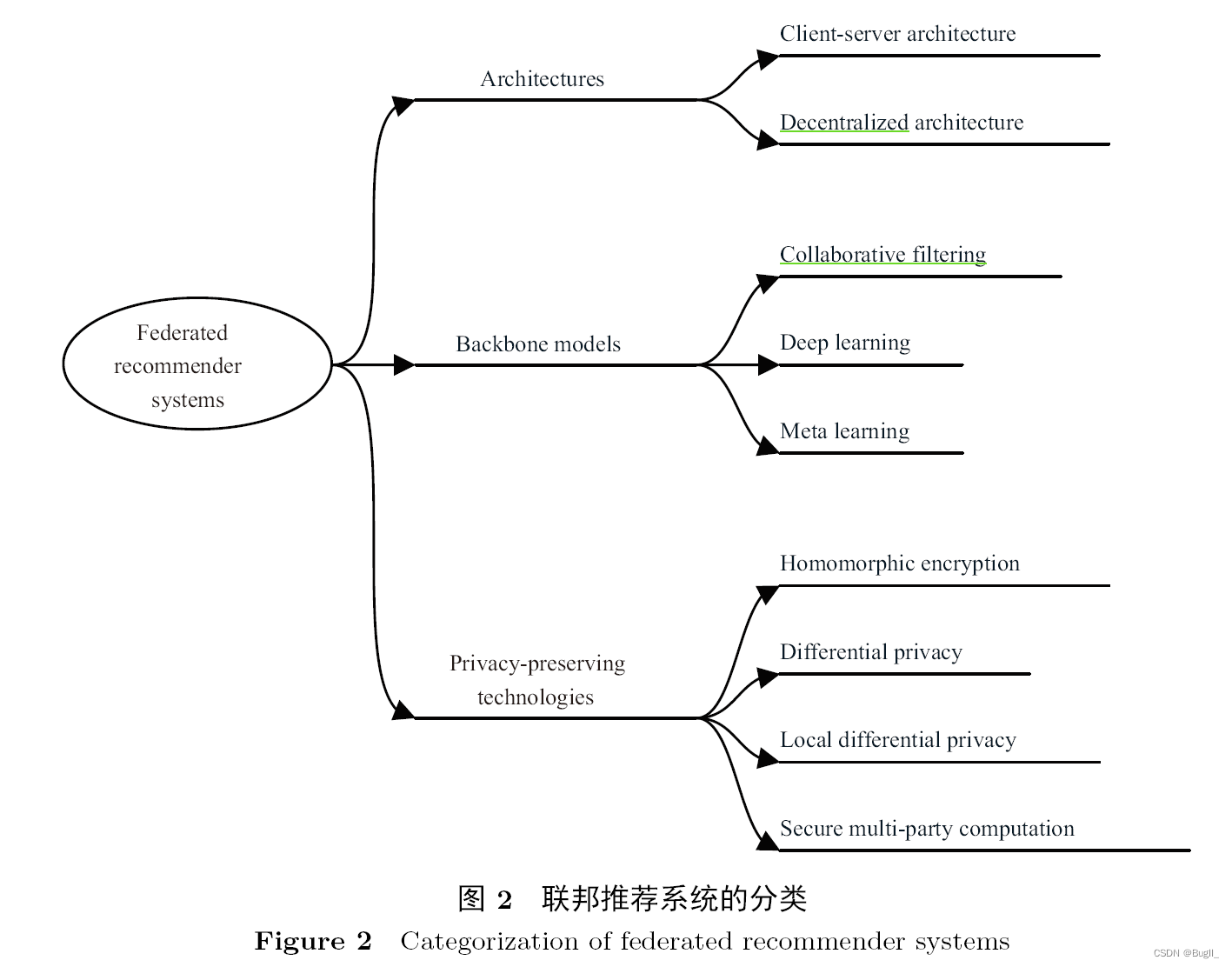
联邦推荐系统是联邦学习领域的关键应用,无论是个人还是机构用户,都必须在不泄露数据的情况下共同进行模型构建。比如,广告联盟就是通过这种方式来精确投放广告。然而,不同应用场景对隐私保护的重视程度不同,模型参数涉及的隐私问题也有所区别。因此,在联邦学习过程中,不同的推荐模型会展现出各自的特性。
推荐算法的深化与隐私
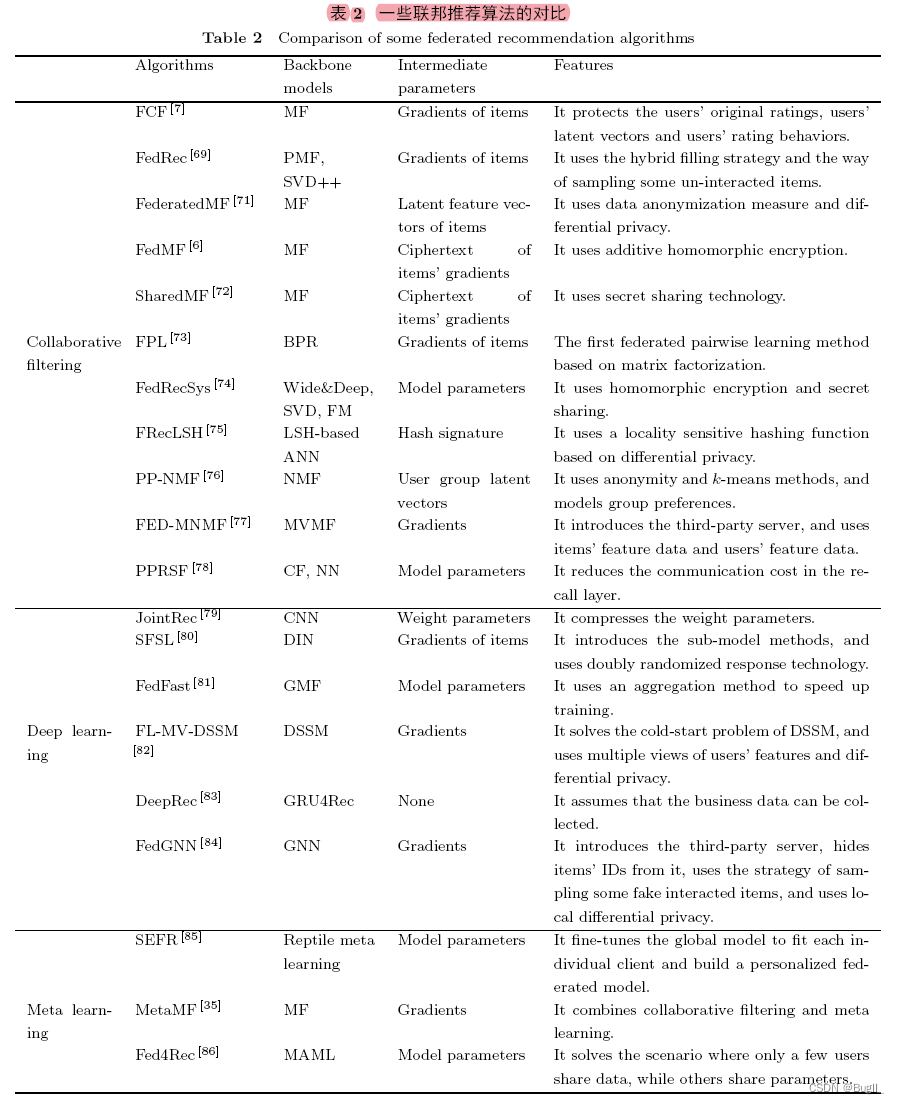
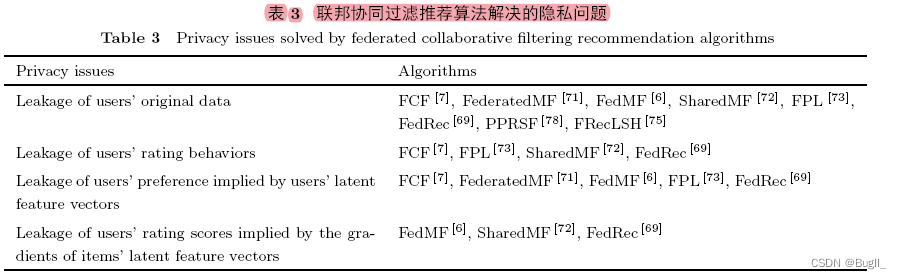
在联邦学习体系中,深度学习驱动的推荐算法的联邦化实现和元学习驱动的推荐算法均构成研究热点。此外,隐私保护技术的运用亦至关重要。例如,在社交网络中推荐好友时,需同时考虑用户间关系的挖掘与隐私的维护。
您对联邦学习在推荐算法领域的看法有何独到之处或额外信息吗?期待您的分享。若您觉得这篇文章不错,不妨点赞并转发。
imkeo.app,tp117.app,btp3.app,tp114.app,bit114.app,tp115.app,bit115.app,imkei.app,tp116.app,btp1.app,btp1.app,im777.app,im555.app,im222.app,im666.app,im444.app,tcoken.im,im333.app,im83.app,tp666.app,tp77.app,tp11.app,tp666.app,tp99.app
