在数据科学领域,数据品质的优劣直接关系到分析的准确性和决策的精确性。然而,在现实操作中,数据往往存在误差和不足。因此,数据清洗成为保障数据可用性的核心步骤。那么,数据清洗具体是如何起到作用的?
数据现状堪忧
从多渠道和实际场景搜集的资料常常存在不少问题。特别是,错误信息和格式混乱的情况十分普遍。比如在电商行业,通过多种途径收集的用户信息中,名字的书写大小写不一致,地址的格式各式各样,这给数据分析师带来了不少麻烦。再者,面对来源复杂、数量巨大的数据集,错误信息就像杂草一样四处丛生,重复和分类错误也成了常见的问题。
数据清理意义重大
数据清理工作确保了信息的精确无误,并且与模型的要求相符,这样有利于模型的处理。这一环节在数据处理的流程中极为关键,数据科学家大约有八成的时间都在从事这项工作。以金融行业为例,优质的数据有助于做出明智的投资决策;而错误的数据则可能导致严重的损失。因此,保证数据的准确性和一致性,就像是给数据安全上了一道保险。
数据错误类型多样
数据重复很常见,特别是在客户信息库中。这可能是由于输入错误或系统不兼容造成的,使得不少客户信息重复出现。这些无关数据会干扰分析,例如在分析学生成绩时,如果混入了他们的家庭娱乐消费数据。还有,异常值也会使分析结果失真,比如在统计员工月薪时,一个特别高的数字就会扭曲整体数据。

清理技术各显神通
在处理数据缺失情况时,研究者一般会用数据集的平均值来填充。以研究天气数据为例,若某观测站某天的气温信息不全,就可以用附近观测站同日的平均气温来补充。对于异常数据,则运用多种数据清洗手段进行识别和剔除,从而保障数据集的完整和相关性。比如,在分析股票价格数据时,那些与整体走势相差极大的数值会被排除。
标准化工作不可少
数据集中的标准化文本至关重要。规范文本的大小写,可以防止错误分类的出现,比如统一将人名的首字母大写。在处理多语言数据时,人工智能技术可以将所有信息转换成同一种语言。以跨国公司的客户反馈为例,借助语言转换工具,可以方便地进行全面分析和有效管理。
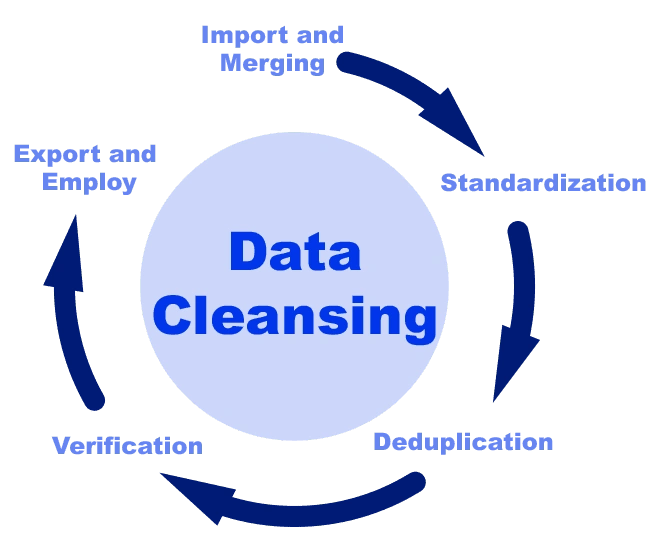
清理步骤严谨进行
数据清理的最后一步是填补数据中的空白。这通常通过估算数值和查阅资料等方法来完成。若此环节出错,后续步骤也可能出现偏差。若前期清理不够彻底,数据分析阶段可能会得出错误的结论和预测。所以,每个环节都必须严谨细致,以保证数据能为决策提供坚实的基础。
工作过程中,你是否曾遭遇过那些难以忘怀的数据失误?若你有过这样的经历,不妨点个赞,并将这篇文章分享出去,让我们一起深入交流讨论。