在现今这个以数据为动力的时代,数据预测的精确度成为了众多行业关注的中心。以本次任务为例,我们需要对四个数据文件中的用户再次购买的概率进行预测,这一过程中遇到了不少难题。这些问题背后既存在挑战,也潜藏着改进的可能,因此,深入研究这些问题是非常有价值的。
给定数据文件
train_data = pd.read_csv("../DataMining/data_format1/train_format1.csv")
test_data = pd.read_csv("../DataMining/data_format1/test_format1.csv")
user_info = pd.read_csv("../DataMining/data_format1/user_info_format1.csv")
user_log = pd.read_csv("../DataMining/data_format1/user_log_format1.csv")
(user_info.shape[0] - user_info["age_range"].count())/user_info.shape[0]
(user_info.shape[0] - user_info["gender"].count()) / user_info.shape[0]
user_log.isna().sum()
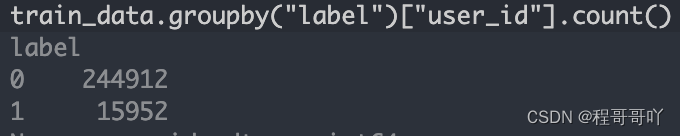
数据文件包括训练数据、测试数据、用户画像和历史记录,它们各自具有独特的作用。训练数据里含有用户、商家信息以及购买情况,对预测至关重要。测试数据则用于计算概率。充分利用这些数据是建立有效预测模型的关键。但若数据组合处理不当,可能会导致失败。有些公司虽然拥有大量数据,却因无法有效整合,导致分析工作难以推进。

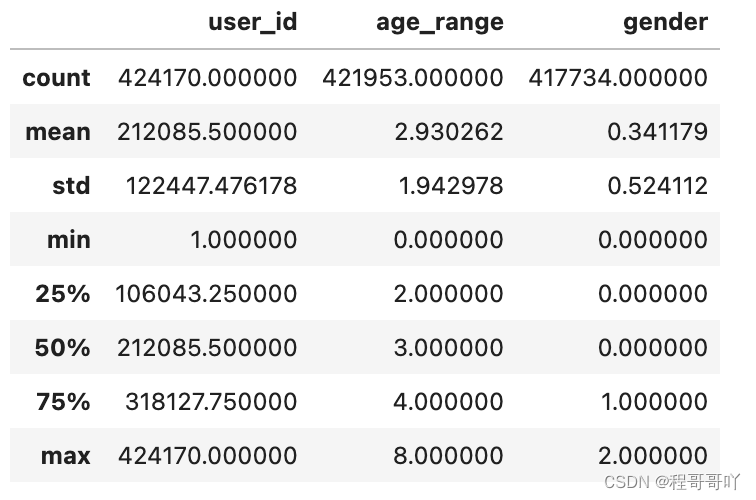
user_info.describe()
数据预处理挑战
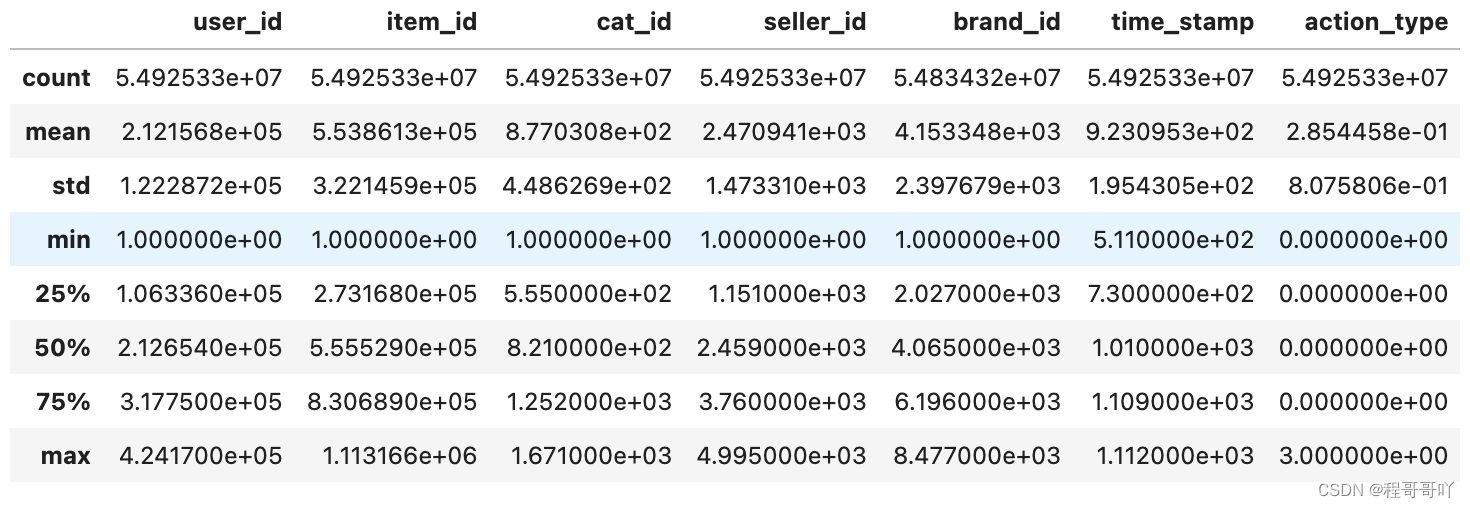
user_log.describe()
在数据加工环节,不能利用插值法来填充那些不连贯特征的空白。即便空白比例不高,我们也采用了特别的方法来处理。然而,数据预处理环节仍存在不少问题。以本案例为例,年龄和性别信息的缺失就接近九万条。在现实操作中,如此大量的数据缺失,就好比建造大楼时缺少了许多关键的砖块。这导致在模型构建时缺乏必要的信息,准确度因此大幅下降。哪怕是一个微小的数据点,也可能对最终的整体结果产生重大影响。
特征工程的瓶颈
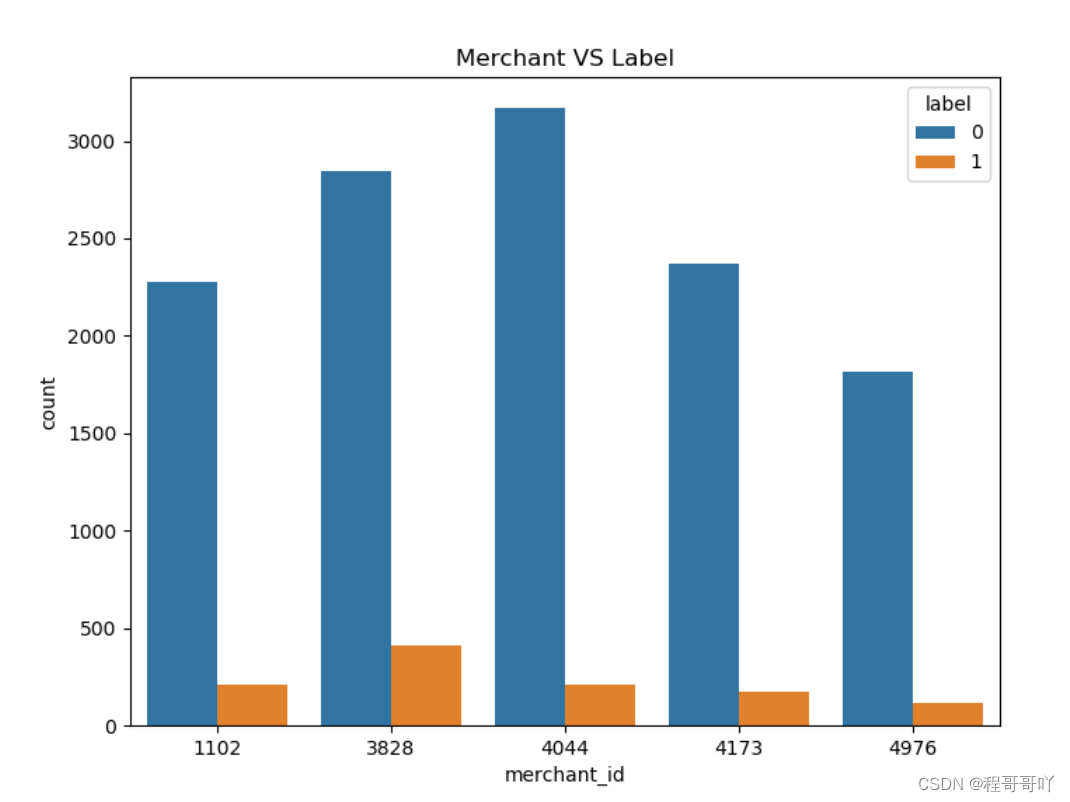
train_data.merchant_id.value_counts().head(5)
train_data_merchant["TOP5"]=train_data_merchant["merchant_id"].map(lambda x: 1 if x in[4044,3828,4173,1102,4976] else 0)
train_data_merchant=train_data_merchant[train_data_merchant["TOP5"]==1]
plt.figure(figsize=(8,6))
plt.title("Merchant VS Label")sax=sns.countplot("merchant_id",hue="label",data=train_data_merchant)
传统特征提取方法有其不足,即便如此,我们仍沿用较为基础的这类方法。然而,若技术或方法停滞不前,一味保守,就好比一辆老旧汽车在高速路上行驶,终将显得力不从心。过去的方法在处理复杂数据时,无论是在适用性还是准确性上,都无法跟上数据发展的步伐。特征工程未能与时俱进,这也使得预测模型的准确性难以保证。
train_data.groupby(["merchant_id"])["label"].mean()
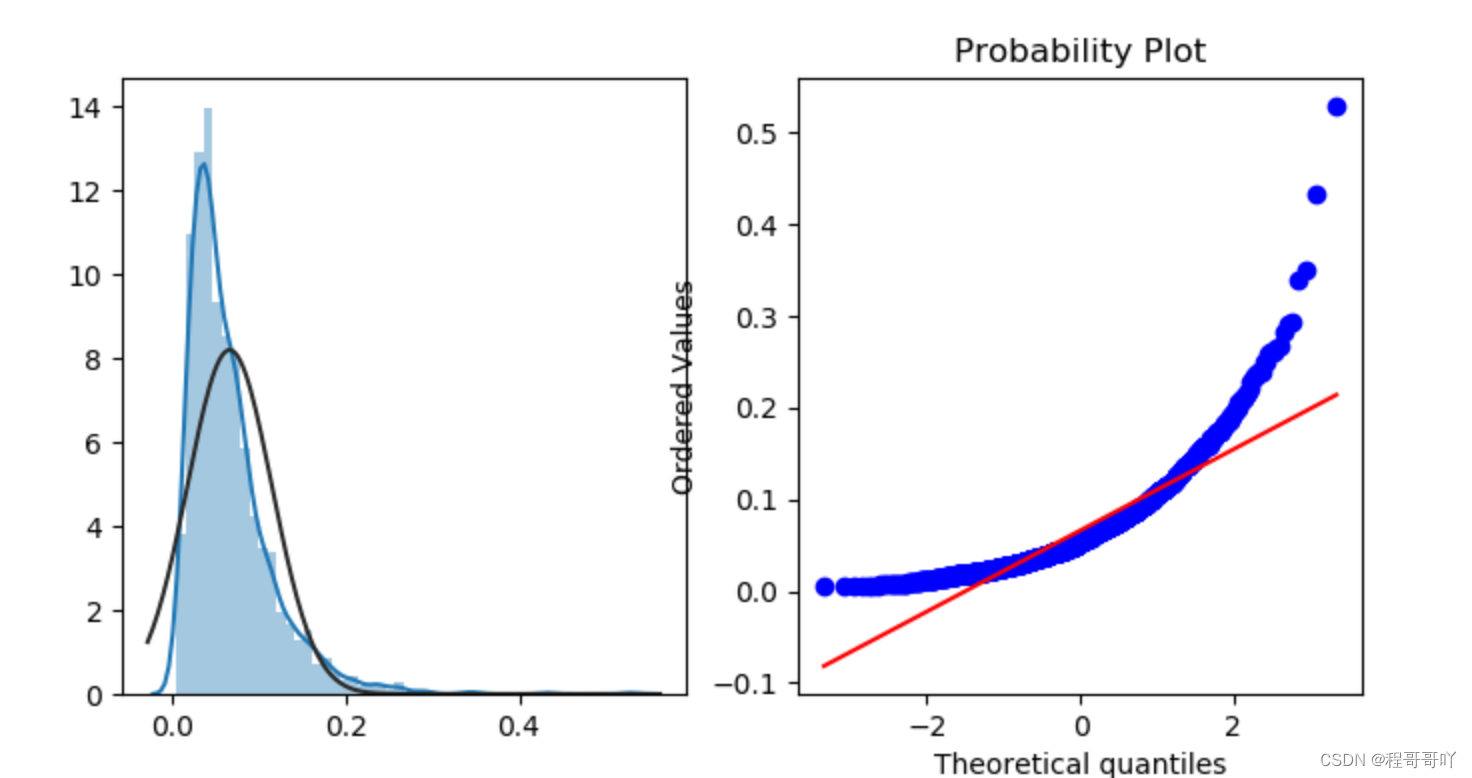
merchant_repeat_buy=[rate for rate in train_data.groupby(["merchant_id"])["label"].mean() if rate<=1 and rate > 0]
plt.figure(figsize=(8,4))
ax=plt.subplot(1,2,1)
sns.distplot(merchant_repeat_buy,fit=stats.norm)
ax=plt.subplot(1,2,2)
res=stats.probplot(merchant_repeat_buy,plot=plt)
模型表现及抉择
实验中采用了多种流行模型,包括逻辑回归、决策树、随机森林和Xgboost。但让人意外的是,这些模型在训练集上的表现并没有显著差异。它们就像几名实力相当的人在选拔赛中难以分出胜负。然而,在测试集中,Xgboost模型却表现突出。这反映出模型在不同数据集上的表现差异显著。因此,选择一个能适应测试数据特征的模型至关重要。实际上,选择错误的模型在职场中是常见的错误,这样的错误会导致在不适配的模型上白费力气。
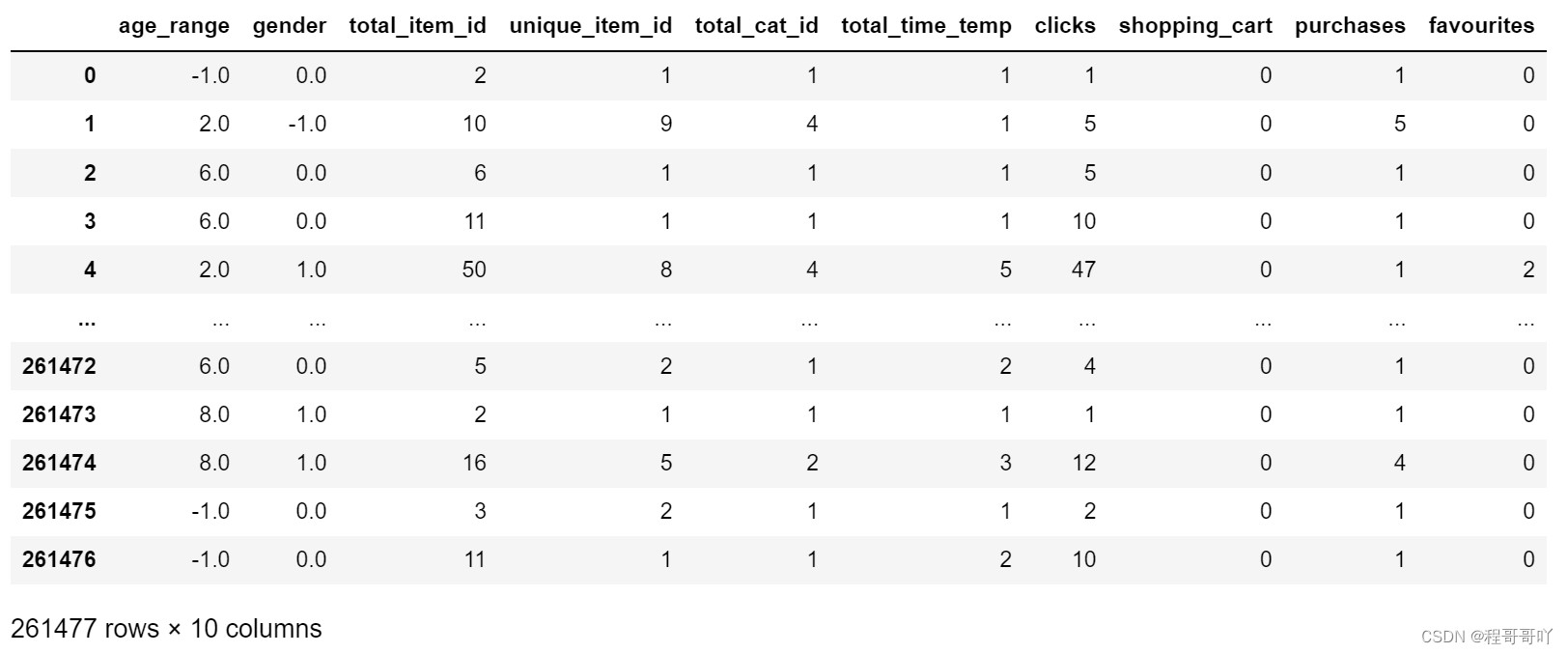
df_train = pd.merge(df_train,user_info,on="user_id",how="left")
调参与最佳模型确定
df_train = pd.merge(df_train,total_logs_temp,on=["user_id","merchant_id"],how="left")
以随机森林模型为例,我们通过调整n_estimators的数值,每次递增10,并用折线图来观察其变化,以确定最佳值。结果显示,当n_estimators设定为100时,模型表现最为出色。虽然这是一个严谨的探究过程,但最终得到的评分0.6256826并不令人满意。在实际操作中,调整参数是一项需要耐心和策略的工作,否则很可能无法找到最优参数。这就像在广阔的海洋中,若没有正确的航向,船只只会离目标越来越远。
#读取数据
df_train = pd.read_csv(r'df_train.csv')
#加载最终测试数据
test_data= pd.read_csv(r'test_data.csv')
test_data
改进计划未来展望
认识到先前的问题,我们打算重新进行特征工程,这就像是重新构建基础。同时,我们计划运用bagging集成方法,融合多种分类算法的理念来优化模型。这就像一支球队调整战术和队员阵容后再次出发。我们采取这些措施,旨在提高未来数据预测的准确性。在当今社会,数据预测的精确度与决策水平、商业利益等众多关键事务紧密相连。
#建模前预处理
y = df_train["label"]
X = df_train.drop(["user_id", "merchant_id", "label"], axis=1)
X.head(10)
#分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=8)
大家对提升数据预测准确性的方案能否达到目标效果有所疑问。欢迎点赞、转发及留言讨论。
#logistic回归
Logit = LogisticRegression(solver='liblinear')
Logit.fit(X_train, y_train)
Predict = Logit.predict(X_test)
Predict_proba = Logit.predict_proba(X_test)
print(Predict.shape)
print(Predict[0:20])
print(Predict_proba[:])
Score = accuracy_score(y_test, Predict)
Score
